Almost everything you do on the Internet is guided by opaque algorithms. Machine-learning-powered sites deliver you your search results, decide whose posts you should see on social media and which of your emails should go to the spam folder. And although I enjoy receiving occasional spam email (because they all prematurely refer to me as Dr Joksas and ask me to give a plenary talk at the hottest neuroscience conference of the year), it’s probably a good thing overall that these algorithms enable us to focus on the important emails. What about everything else though? It seems that in the last few years it became more difficult to find relevant information. Exponential growth of information is partly to blame, but it might also be a result of a very basic incentive misalignment—what the tech companies want is different from what we want.
One of the most fundamental ways in which machine learning has shaped the Internet since 2012 is in the personal tailoring of content to each of us. Before that, social media sites (as an example) used to serve us content in a chronological order; that is either no longer an option on most of these sites, or is a well-hidden opt-in feature that they prefer you would not use at all. By tracking our behavior, they can now train neural networks to serve us content in such a way that maximizes some objective measure, like the time spent on their platform. Why they would do it is obvious—more time spent on their website means more ads shown to us which means higher revenues. The content that’s tailored to us is marketed as “relevant”, but a more accurate term would be “addictive”. There is maybe 2-minutes’ worth of relevant content on your Twitter feed every day, but even that little amount is hard to uncover.
So in a world of infinite streams of information and algorithms trying to manipulate us, how do we find the news that is relevant to us, how do we get updates from people whose opinions we care about, and, more generally, how do we interact with the Internet? Do we each train our personal neural networks that would learn what each of us cares about? NO! In a world of complexity, we should not seek to introduce additional complexity. What we need is simplicity and for that we will have to go back in time!

Where We’re Going, We Don’t Need Machine Learning
More than 20 years ago, a technology, called RSS (Really Simple Syndication), emerged. Its aim was to keep track of many different websites so that the users wouldn’t have to check for updates manually in each one of them. For example, if you were interested in news sites X and Y, and a blogger Z, you could subscribe to their RSS feeds and get notified whenever a new piece of content would come out. How? Using an RSS feed reader that automatically checks for updates in those feeds and then aggregates the content in one place. I know this may sound a bit confusing and given that I am obviously advocating for RSS as a replacement for social media (besides other things) when it comes to us getting updates about the world, I think it makes sense to explain how it really works. Because what is the point otherwise? If you cannot explain the basic principles behind RSS and what its limitations are, it might seem no better than using social media to interact with the Internet.
So how does RSS work?
RSS uses XML files to encode information. These are just simple text files that are usually used for structured data. In the case of RSS, they can be used to describe individual items of content in a feed. Let me illustrate it with an example. Suppose I wanted to make an RSS feed for my blog; I could create an XML file like this1:
<rss>
<channel>
<title>dovydas.com Blog</title>
<link>https://dovydas.com/blog/</link>
<description>This is my blog!</description>
<item>
<title>Colorblind-Friendly Diagrams</title>
<link>https://dovydas.com/blog/2020-07-06-colorblind-friendly-diagrams/</link>
<pubDate>06 Jul 2020</pubDate>
<description>This is my second blog post!</description>
</item>
<item>
<title>Do Not Trust WhatsApp</title>
<link>https://dovydas.com/blog/2020-07-01-do-not-trust-whatsapp/</link>
<pubDate>01 Jul 2020</pubDate>
<description>This is my first blog post!</description>
</item>
</channel>
</rss>
In this file, I defined an RSS feed (using <channel> tags) for my blog and named it “dovydas.com Blog” (using <title> tags). Additionally, I added two blog posts (using <item> tags) with specific titles (using <title> tags). For both the feed and individual posts, I included URLs (using <link> tags) and short descriptions (using <description> tags). Finally, I included publication dates (using <pubDate> tags) for both blog posts.
Now that the file is prepared, I could essentially store it anywhere on my website so that others could access it. Visitors to the site would copy the URL to that file and then paste it into their RSS reader. That RSS reader would download the file and display the various elements of the feed to the user. For example, my RSS reader of choice would display this feed in the following way:
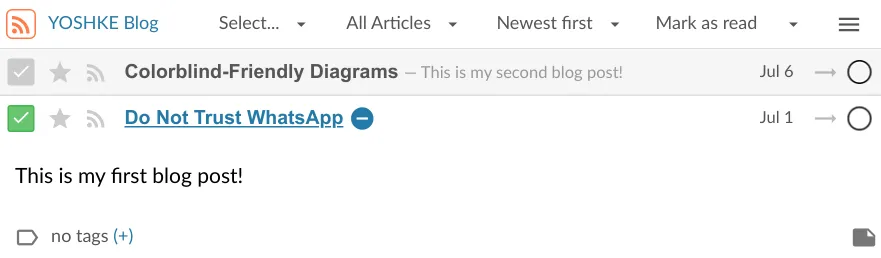
We can see that the RSS reader presented all the information that we specified in the XML file: blog name, blog post titles, publication dates and descriptions. Additionally, I can press on the titles of individual posts and the RSS reader will redirect me to my website because the URLs were specified.
All RSS readers update the feeds at some regular intervals, i.e. they download and process the XML file again. So, whenever I, as an owner of a website, want to add a new piece of content to the website, I should also update the XML file containing the RSS feed. That is the only way in which RSS readers will be able to detect any changes.
And that’s it! It’s that simple. RSS feed is just a text file that presents content in a structured, machine-readable format.
How to use RSS?
Most RSS readers allow you to subscribe to as many feeds as you want. Here is what my own general feed is usually like:

I know that content-wise this looks like social media and appearance-wise it looks like an email client. The reason I prefer RSS over social media though is because I get updated about everything—news, Twitter, YouTube, blogs, podcasts, and more—in one place, the results are not filtered by some machine learning algorithm and I can process the information in any way I want.
Similar to the way email clients allow you to take care of your emails, most RSS readers enable you to categorize the feeds, add your own tags and organize them the way you prefer. That is the beauty of text files—they are simple, but they allow you to add a lot of modular functionality. For example, some RSS readers might provide the option to process your feeds using regular expressions. Suppose you subscribed to a dozen technology-oriented RSS feeds but were mostly interested in robotics. You could tell your RSS reader to mark any RSS item with a tag “robotics” if it contained a string “robot” in its title or description. That way, you could easily focus on the news that you are most interested in.
The Arrow of Time
Technologies tend to become more accessible over time. Whether it is building websites, writing LaTeX documents or training image classifiers, tools are constantly being developed that allow people without in-depth knowledge to effortlessly use these technologies. The same could be said of RSS, which saw the development of hundreds of feed readers in forms of websites, desktop applications, browser extensions and even terminal applications. Unfortunately, these advances in ease of use have been canceled out by an active opposition to the adoption of RSS in a large number of sectors. In surveillance capitalism, there exist incentives not only to track user behavior, but also to oppose any technology that prevents you from doing it.
The most blatant example of this behavior is, obviously, social media companies. Both Facebook and Twitter used to offer RSS feeds, but that is no longer the case. It is quite amusing that Facebook still recognizes the power of RSS, although in a very selfish way. They have this feature called instant articles that allows publishers to submit their articles to Facebook using RSS or other methods. They claim it improves loading times on mobiles, but obviously their goal was to increase their own tracking capabilities even further which is possible now that these articles are hosted on their platform.
There is some hope though. In media that do not rely on such an extreme user tracking you still see some support for RSS. A large proportion of news outlets still offer their own RSS feeds where they put summaries of the articles and link back to their website. Some non-profit publications, such as Quanta Magazine, can even afford to put the whole content of their articles inside the RSS feeds—that way the users can read the articles even without leaving their RSS readers. I too put my full blog posts inside my RSS feeds; I do not place any ads on my website and so do not care whether people access the posts directly or through their feed readers2.
But just because someone relies on ads to generate revenue, does not necessarily mean they cannot utilize RSS. Podcasts are the best example of this. They are, almost by definition, RSS feeds—podcast creators add a new RSS item for each episode and associate it with an audio file that anyone can download. That is the reason they do not have to upload each episode manually to Spotify, iTunes, Google Podcasts or wherever else people listen to podcasts—all these services read the RSS feeds automatically. Podcasters usually earn money by doing dumb ads, i.e. ads that are not personalized. Because of their simple format, they can simply be read out during each episode and thus be embedded in the audio file; a link to that file is part of the RSS feed. So, no. RSS does not prevent you from making money.
Overall, I have mixed feelings about the future of RSS and the Internet in general. Sure, there are people who create tools for constructing RSS feeds of websites that do not offer them, but it’s a constant struggle—someone finds a way to automatically extract Facebook posts and then Facebook changes its interface, after which the cycle repeats. I am also not optimistic about how many people would be willing to go back to a more primitive technology, even if it gives them more control. And yet I see no other way. In a world where there is a widespread belief that advertisers must know customers’ religious beliefs and a thousand other things to successfully sell them a teapot, we will naturally converge towards more addictive social media and more intrusive tracking. Only by rejecting these business models completely can we incentivize the tech companies to change. In the meantime, RSS seems like a good enough alternative.
This is a simplified example that is missing a lot of standard tags. ↩︎
The exception is posts that include math typography (which requires JavaScript). Although I still include these posts in my RSS feeds, I also add a note saying that they will not be rendered correctly in RSS feed readers and they should instead be read directly on my website. ↩︎